
TECHNOLOGY
Why 24ot1jxa Harmful: The Hidden Cyber Threat You Need to Know

Introduction to why 24ot1jxa harmful
Cyber threats are evolving at an alarming pace, and staying informed is crucial for protecting your digital life. One particular threat that has raised red flags in the cybersecurity community is why 24ot1jxa harmful malware. But what exactly makes this malicious software so dangerous? As we delve deeper into the nature of 24ot1jxa, you’ll discover why it’s not just another run-of-the-mill virus but a serious concern for anyone using connected devices. Understanding how it spreads and recognizing its signs can be your first line of defense against potential data loss and financial ruin. Let’s explore everything you need to know about this hidden cyber threat!
How Does 24ot1jxa Spread?
24ot1jxa is particularly insidious in its distribution methods. It often relies on unsuspecting users clicking on malicious links or downloading infected files. These may appear as legitimate software updates or enticing advertisements.
Phishing emails are another common tactic used to spread this malware. Cybercriminals craft messages that look genuine, tricking victims into revealing sensitive information or inadvertently installing harmful software.
Social media platforms can also act as conduits for 24ot1jxa. Users might encounter posts containing compromised links, leading them down a dangerous path without realizing it.
Infected USB drives represent yet another risk factor. Plugging an unknown device into your computer can quickly unleash the malware onto your system, creating widespread chaos before you even notice something is wrong. Staying vigilant and cautious online is essential to avoid falling prey to these tactics.
The Dangers of 24ot1jxa
The dangers of 24ot1jxa are alarming and extensive. This malware can silently compromise your sensitive data, leaving you vulnerable to identity theft. Once it infiltrates your system, it may access personal information like passwords and banking details.
Moreover, 24ot1jxa can turn your device into a zombie in a botnet. Cybercriminals use these networks for various malicious activities, including launching attacks on other systems or distributing more malware.
Your device’s performance might also take a hit. Frequent crashes and sluggish operations are common signs of infection. As the malware spreads, it often creates backdoors for even more dangerous threats to invade.
Additionally, some variants download further harmful software without any warning. This escalation makes removing the initial threat all the more complicated and risky for users who underestimate its impact.
Signs of an Infected Device
Detecting an infected device is crucial for your cybersecurity. Keep an eye out for unusual behavior that raises red flags.
First, you might notice unexpected pop-ups or ads appearing while browsing. These can signal the presence of malware like 24ot1jxa.
Another sign is sluggish performance. If apps take longer to load and tasks feel laggy, it could be a result of hidden threats consuming resources.
Frequent crashes or sudden restarts are also concerning indicators. An infected device may struggle to maintain stability.
Look for unfamiliar programs installed without your permission. Malware often sneaks in alongside legitimate software, making its removal tricky.
Monitor network activity. An unexplained spike in data usage can suggest malicious processes running in the background, potentially linked to 24ot1jxa’s operations. Stay vigilant; these signs matter!
Steps to Protect Your Device from 24ot1jxa
To safeguard your device from 24ot1jxa, start by installing a reputable antivirus program. Regular updates are crucial for keeping your defenses strong against evolving threats.
Enable firewalls on your devices. These act as barriers, blocking unauthorized access and keeping malicious software at bay.
Be cautious with email attachments and links. Phishing attempts often use these tactics to spread malware like 24ot1jxa. Always verify the sender’s identity before clicking anything suspicious.
Regularly back up your data. In case of an infection, you can restore important files without losing everything.
Keep all software updated, including operating systems and applications. Developers frequently release patches to close vulnerabilities that cybercriminals exploit.
Educate yourself about cybersecurity best practices. Awareness is key in recognizing potential threats before they cause damage.
What to Do if Your Device is Infected
If you suspect that your device is infected with 24ot1jxa, immediate action is crucial. First, disconnect from the internet. This helps prevent further data loss or communication with the malware’s server.
Next, run a full scan using a reputable antivirus program. Ensure it’s updated to catch the latest threats effectively.
After detecting and removing any malicious files, change all of your passwords—especially for sensitive accounts like banking or email. Use another device if possible to avoid re-infection while doing this.
Consider restoring your system to an earlier point before the infection occurred if available. Backup your important files regularly so that you can recover them without hassle in such situations.
Stay vigilant after cleaning up; monitor your devices for unusual activity indicating residual effects of the malware. Keeping software updated will also bolster defenses against future attacks.
Conclusion and Final Thoughts
The rise of cyber threats is a pressing concern for everyone who uses technology. Understanding why 24ot1jxa is harmful can empower you to safeguard your devices and personal information. This malware not only compromises your device’s functionality but also poses serious risks to your privacy and security.
By recognizing how 24ot1jxa spreads, being aware of the signs of infection, and taking proactive steps towards protection, you can significantly reduce the risk it presents. If you suspect that your device has been infected, swift action is crucial in mitigating damage.
Staying informed about threats like 24ot1jxa is essential in our digital age. Awareness leads to better practices that protect both you and your data from harm. Take charge of your online safety today; vigilance is key against evolving cyber dangers.
ALSO READ: Cyber Insurance Coverage Silverfort Impact on Cybersecurity
FAQs
What is “Why 24ot1jxa Harmful”?
“Why 24ot1jxa Harmful” refers to the growing concern about 24ot1jxa malware — a dangerous cyber threat designed to steal personal data, slow down devices, and create backdoors for further attacks. This article explores why it’s more than just a typical virus and how you can protect yourself.
How can 24ot1jxa malware enter my device?
24ot1jxa spreads through malicious links, phishing emails, infected USB drives, and fake software updates. It can also use social media posts with hidden links, making it crucial to stay cautious online.
What are the warning signs of a 24ot1jxa infection?
Key signs include unexpected pop-ups, sluggish device performance, random crashes, unfamiliar apps appearing on your system, and unexplained spikes in network activity.
Can antivirus software detect and remove 24ot1jxa?
Yes, most reputable antivirus programs can detect and remove 24ot1jxa, but keeping the software updated is essential. Running regular scans and enabling firewalls will strengthen your defense.
What should I do immediately if I suspect 24ot1jxa has infected my device?
Disconnect from the internet, run a full antivirus scan, remove detected threats, change all your passwords, and consider restoring your system to a previous clean state. Monitor your device for any further suspicious activity.

In the past few years, we saw 5G completely engulf the world of smartphone and internet technology. Not many of us knew the full scale of 5G, like the fact that 5G has the potential to replace your conventional internet connection. Well, the idea of getting rid of messy wires sure is tempting but there are several factors to consider before making that call.
In this blog, we will discuss the advantages and disadvantages of 5G and how it measures up against other wired and wireless connections.
In This Blog
Advantages of 5G.. 1
1. Lower Latency Than Satellite Internet 1
2. No Need for Clear Line of Sight Like WISPs. 1
3. Cost 2
4. Better Coverage and Accessibility. 2
5. Convenience. 2
Disadvantages of 5G.. 2
1. Performance. 2
2. Speed Tiers. 3
3. Upload Speeds. 3
Summing Up. 3
Advantages of 5G
Let’s discuss some advantages and other implications of getting 5G for your home.
1. Lower Latency Than Satellite Internet
Wireless internet technology for homes is not an entirely new concept. Satellite internet provides online connection; however, 5G is an improved wireless technology. With all its virtues, satellite internet still bogs you down with limited speeds, range, and latency.
It suffices for activities that are not data-intensive, like browsing, but for real-time applications, you need a stronger connection.
2. No Need for Clear Line of Sight Like WISPs
There are also Wireless Internet Service Providers(WISPs) that commonly use frequencies other than 5G to beam internet signals from access points on towers or buildings to home modems. They do this with the help of attached antennas.
Even though WISPs minimize latency issues, there is still a requirement for a clear line of sight between the access point and the home antenna to ensure a unidirectional beam of signals. 5G provides high speed and low latency without needing a clear line of sight.
3. Cost
This advantage is subject to the kind of providers available in your area and the packages they offer. Typically, a 5G connection costs an economical amount for an adequate signal compared to wired connections.
The cherry on top would be if you can find a 5G connection from your existing provider, you may be able to find a nice bundle package with both connections.
4. Better Coverage and Accessibility
Satellite internet Providers and WISPs usually target folks in underserved rural areas who might not have adequate options for a wired internet service. 5G is making inroads even in areas where consumers could easily get cable or fiber. This fulfills a need for an accessible and improved wireless internet connection.
5. Convenience
Convenience is a big draw that 5G offers. If you don’t already have cable or fiber lines running to your house, you don’t have to wait around for a technician to come and do an installation between specified hours. Not to mention, you can finally get rid of that horrid bunch of wires.
Even if you have a cable or fiber connection, 5G eliminates the complications of ethernet jacks and modem placements. All you have to do is plug in a 5G receiver wherever you can find a power socket.
Disadvantages of 5G
Despite the aforementioned advantages, 5G also has some potential pitfalls. Let’s expand on them.
1. Performance
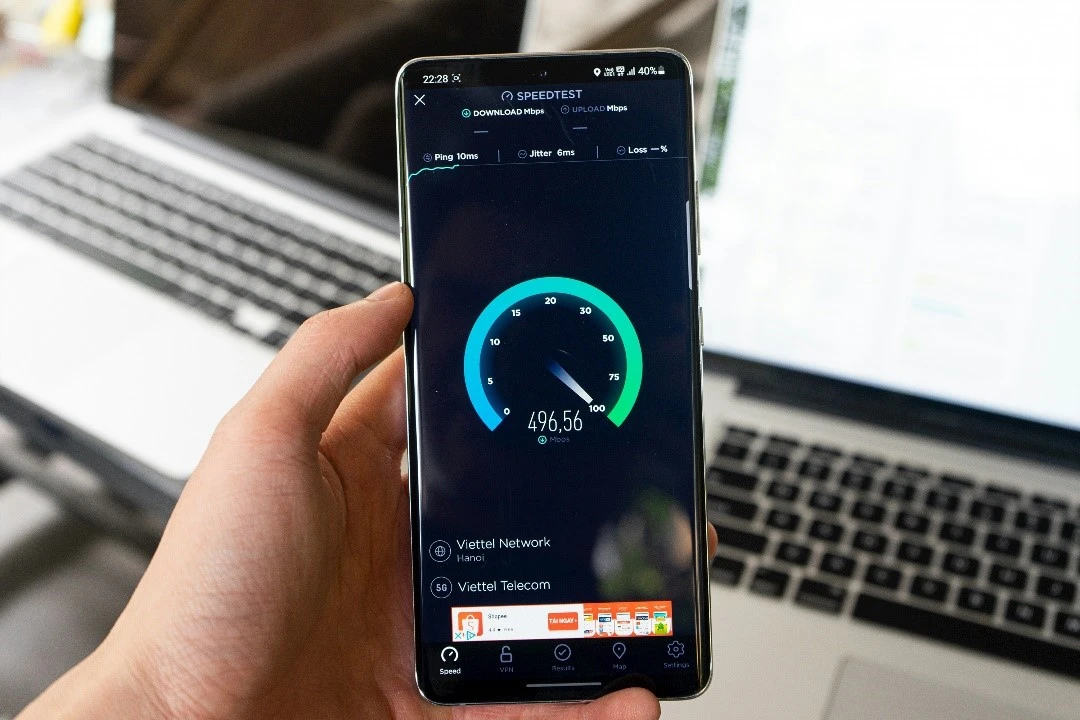
How well your 5G connection performs is completely dependent on the quality of the 5G signals you get in your house. 5G speeds simply aren’t high enough everywhere to compete with cable or fiber. One strategy is to run a speed test to get a rough idea of the performance you’ll get with home 5G.
As for performance, you can expect speed and latency to fluctuate more, compared to a wired connection which can be much more stable. This is because the network tends to have variable loads and wireless signals are dominantly inconsistent. If you’re looking for an internet for things that need a stable connection, its better to go for internet, like the one offered by Spectrum, rather than a 5G provider.
2. Speed Tiers
How well your 5G connection works is also subjective to various speed tiers. The ultra-fast one has a very short-range, millimeter wave. The low band 5G does not differ much from 4G LTE in terms of performance. Here’s the snag, some of the faster versions of 5G don’t penetrate through walls as well as 4G.
If you’re in doubt about exactly what kind of 5G technology and ISP you’re considering, make sure you do your research. This is because some providers that advertise 5G will often fall back to a 4G LTE connection if the actual 5G connection reaching your home is not strong enough.
A lower band connection can give you better signal strength, which comes at the cost of slower speeds. Low band 5G, around 700 megahertz, is often marketed as rural broadband with reliability as a big selling point.
3. Upload Speeds
Considering you have an ISP in your area offering fiber, they’ll usually offer upload speeds that are just as fast as download speeds. This is the case with most home cable connections. However, when it comes to 5G, you might you may experience some choppy upload speeds with 5G home internet.
Summing Up
Latency is not a big factor if you’re just trying to download large files or watch YouTube. If you’re in an area with good 5G coverage, and aren’t super worried about online gaming performance or video conferencing, 5G home internet might just be worth looking into. But, for someone who wants a reliable, stable connection, fiber internet is still something you should get.

Introduction to Boltból
Welcome to the world of Boltból, where innovation meets practicality. This cutting-edge technology is not just a trend; it’s a transformative force reshaping how industries operate and thrive. With its roots in advanced research and development, Boltból has quickly become synonymous with forward-thinking solutions that push boundaries.
Imagine harnessing unique capabilities that streamline processes, enhance productivity, and foster creativity across various sectors. As we dive deeper into what Boltból offers, you’ll discover how this remarkable tool can be a game-changer for businesses looking to stay ahead in a competitive landscape. Let’s explore the journey of Boltból from its inception to its future potential prepare to be inspired!
The History and Evolution of Boltból
Boltból began its journey in the early 2000s as a small startup focused on harnessing technology to drive innovation. The founders envisioned a platform that would connect ideas with execution, bridging gaps across various industries.
As it evolved, boltból adopted cutting-edge technologies like AI and blockchain. This shift allowed it to provide enhanced data security and efficiency, making waves in sectors from healthcare to finance.
Over the years, boltból expanded its offerings by integrating user feedback into product development. This adaptability became one of its hallmarks, ensuring relevance amid rapid technological changes.
The introduction of collaborative tools transformed how teams worked together. With an emphasis on real-time communication and seamless project management, boltból established itself as a leader in fostering innovative environments for businesses worldwide.
Innovative Features and Advancements in Boltból Technology
Boltból technology stands at the forefront of innovation. Its unique features set it apart in the ever-evolving tech landscape.
One standout advancement is its real-time data processing capability. This allows businesses to make decisions based on up-to-the-minute information. Speed and accuracy are essential in today’s market, and Boltból delivers both.
Another impressive feature is its user-friendly interface. Even those with minimal technical skills can navigate through complex tasks effortlessly. This accessibility opens doors for a broader range of users.
Additionally, Boltból prioritizes security with advanced encryption protocols. Protecting sensitive data has never been more critical, and this focus ensures peace of mind for companies across various sectors.
Integration capabilities are also noteworthy; Boltból seamlessly connects with existing systems, enhancing overall efficiency without requiring a complete overhaul of current infrastructures. These advancements solidify Boltból’s position as a game-changer in technology solutions.
Impact and Benefits of Boltból on Industries
Boltból is revolutionizing industries across the globe. Its advanced technology streamlines operations, making processes faster and more efficient.
Manufacturing sectors are seeing significant improvements in productivity. Automation powered by boltból ensures precision, reducing waste and enhancing quality control.
In healthcare, boltból enhances patient care through improved data management systems. Real-time updates allow for quicker decision-making and better outcomes.
Retail businesses benefit from personalized customer experiences. Boltból analyzes consumer behavior to tailor offerings, boosting sales and customer loyalty.
Moreover, logistics companies leverage boltból for smarter supply chain solutions. It optimizes routes and inventory levels, cutting costs while improving service delivery.
Energy sectors embrace boltból’s innovations for sustainable practices. Smart grids driven by this technology promote efficiency and reduce environmental impact.
As various industries adopt boltból, they not only enhance their operational capabilities but also position themselves as leaders in innovation.
The Future of Boltból: Predictions and Possibilities
As we gaze into the horizon of boltból, its potential seems limitless. Emerging technologies are set to redefine how businesses implement this innovation.
We can expect advancements in artificial intelligence integration with boltból systems. This will enhance decision-making processes and streamline operations significantly.
Moreover, as sustainability becomes a priority across industries, boltból may pivot towards greener solutions. The drive for eco-friendly practices could lead to innovative approaches that resonate well with consumers.
Collaboration is another exciting avenue. We might witness partnerships between various sectors leveraging boltból for cross-industry innovation.
Furthermore, data security will take center stage as more organizations adopt these technologies. New protocols will emerge to safeguard sensitive information while maintaining efficiency.
The journey ahead for boltból is brimming with possibilities that can revolutionize existing frameworks and inspire new models of growth.
Case Studies: Success Stories of Companies Using Boltból
Companies across various sectors have embraced boltból, showcasing its transformative power. One standout example is a mid-sized logistics firm that integrated boltból technology to streamline operations. By automating inventory management, they reduced errors and improved delivery times significantly.
Another inspiring case comes from the healthcare industry. A hospital adopted boltból solutions for patient data management. This adoption enhanced communication among departments and accelerated decision-making processes, leading to better patient outcomes.
In the retail sector, a popular e-commerce platform utilized boltból for personalized customer experiences. Through advanced analytics and AI-driven recommendations, they saw an increase in sales conversions by 30%.
From logistics to healthcare and retail, these success stories highlight how versatile boltból can be when tailored to meet specific business needs. Each company not only benefited financially but also gained a competitive edge in their respective markets.
Challenges and Limitations of Boltból
Despite its innovative nature, boltból faces several challenges that can hinder its widespread adoption. One significant concern is the steep learning curve associated with integrating this technology into existing systems. Many businesses struggle to train their workforce effectively.
Moreover, there are potential security risks linked to boltból’s implementation. As more data flows through interconnected devices, vulnerabilities may arise, exposing sensitive information to cyber threats.
Cost is another factor that cannot be overlooked. The initial investment for boltból technology can be substantial. Smaller enterprises might find it difficult to allocate the necessary resources.
Additionally, regulatory hurdles often complicate the deployment of boltból solutions across various industries. Compliance with local laws and regulations requires careful navigation and planning.
Not all sectors will benefit equally from boltból’s advancements. Some industries may find it challenging to adapt or see a tangible return on investment in a timely manner.
How to Incorporate Boltból into Your Business Strategy?
To effectively incorporate boltból’s into your business strategy, start by evaluating your current processes. Identify areas where innovation can enhance efficiency or drive growth.
Next, consider how boltból’s technology aligns with your goals. Whether it’s streamlining operations or enhancing customer experience, ensure that the integration supports your vision.
Training is crucial. Equip your team with the necessary skills to leverage boltból’s features fully. This might involve workshops or online courses tailored to their needs.
Collaboration fosters creativity. Engage cross-functional teams in brainstorming sessions about potential uses of boltból’s within various departments.
Monitor progress and gather feedback regularly. This will allow for adjustments and improvements as you adapt to this innovative tool over time. Embracing a flexible approach ensures that your incorporation of boltból’s remains relevant and impactful in an ever-changing landscape.
Conclusion
Boltból’s stands at the forefront of innovation, reshaping how industries operate and adapt to modern challenges. Its history reflects a commitment to advancement, evolving through various technological leaps that have positioned it as a vital tool across sectors. The unique features of Boltból’s enhance efficiency and effectiveness, proving essential for businesses looking to stay competitive.
The impact of Boltból’s is evident in its ability to streamline processes and improve productivity. Companies leveraging this technology have reported significant benefits, from cost savings to enhanced customer satisfaction. As we look toward the future, predictions suggest even greater advancements will emerge, expanding the possibilities for what can be achieved using Boltból’s.
Success stories abound as organizations share their experiences with Boltból’s implementation. These case studies highlight practical applications and measurable results that inspire others in their journey towards innovation. However, it’s also important to acknowledge the challenges and limitations associated with integrating new technologies like Boltból’s into established business structures.
For those considering adoption, understanding how best to incorporate Boltból’s into existing strategies is crucial for maximizing potential gains. Engaging with experts or seeking tailored solutions can pave the way for successful integration.
As businesses continue exploring options within this innovative landscape, staying informed about developments surrounding boltból’s remains essential for anyone aiming to thrive in an increasingly digital world.

Introduction to Assumira
In a world where digital interactions shape our daily lives, the demand for seamless and engaging online experiences is at an all-time high. Enter Assumira—a groundbreaking solution designed to revolutionize how businesses connect with their audiences in the digital realm. With technology evolving faster than ever, organizations need tools that not only keep pace but also elevate user engagement to new heights. Whether you’re a small startup or a large enterprise, Assumira promises to transform your approach to digital transformation and enhance every interaction along the way. Let’s explore what makes Assumira stand out in this competitive landscape and how it can help you thrive in an increasingly complex digital environment.
The Need for Digital Transformation
Modern enterprises are currently contending with an unparalleled rate of transformation within the marketplace. Customer expectations are evolving rapidly, driven by technology advancements.
Companies that hesitate to adapt risk falling behind competitors. Digital transformation isn’t merely a trend; it’s a necessity for survival in the modern marketplace.
Organizations must rethink their strategies, processes, and customer interactions. Embracing digital tools can lead to streamlined operations and enhanced decision-making capabilities.
Moreover, companies that harness data analytics gain valuable insights into consumer behavior. This enables personalized experiences that foster loyalty and trust with customers.
In an age where agility defines success, those who embrace digital transformation will thrive. The era of traditional business models is fading fast as new opportunities emerge through innovation and connectivity.
How Assumira is Changing the Game?
Assumira is revolutionizing the digital interaction framework by blending advanced technological solutions with a design philosophy centered entirely on the user.
At its core, Assumira harnesses data analytics and AI to personalize experiences like never before. This allows businesses to connect with their audiences in meaningful ways.
Automated content distribution guarantees that each engagement is personalized and perfectly aligned with individual user needs. Users are not just passive observers; they become active participants in their journey.
Scalability is another game-changer. Companies can adapt quickly as market demands shift, ensuring they remain competitive without compromising on quality or engagement.
Furthermore, Assumira’s seamless integration capabilities mean that existing systems work harmoniously with new solutions. Businesses can evolve effortlessly while maintaining operational integrity.
With such transformative potential, it’s clear why Assumira stands out as a leader in digital innovation today.
Key Features and Benefits of Assumira
Assumira stands out with its intuitive interface, making digital experiences seamless. Users can navigate effortlessly, ensuring that complexity doesn’t impede creativity.
A core feature is real-time analytics. Businesses gain insights instantly, allowing them to pivot strategies as needed. This data-driven approach transforms decision-making processes.
Customization options are abundant within Assumira. Brands can tailor their interfaces to reflect their unique identities. This personalized touch fosters stronger connections with users.
Collaboration tools enhance teamwork across departments. With a shared platform for communication and project management, teams stay aligned and productive.
Security remains paramount in the digital landscape. Assumira places a premium on rigorous protocols to safeguard user information and uphold the enduring credibility of its brand.
Scalability means businesses of any size can leverage Assumira’s capabilities without restrictions, adapting as they grow or evolve their needs over time.
Success Stories: Real World Examples of Assumira’s Impact
Assumira has transformed numerous businesses, showcasing its powerful capabilities across various sectors.
One standout example is a mid-sized retail chain that struggled with customer engagement online. After implementing Assumira’s solutions, they saw a 40% increase in website traffic and a significant boost in conversion rates within months.
A healthcare provider also experienced remarkable results. By utilizing Assumira’s digital analytics tools, they streamlined patient interactions. This led to improved appointment scheduling and higher satisfaction scores among patients.
In the financial sector, an investment firm adopted Assumira to enhance their client communication strategies. The outcome? A notable rise in client retention and an overall enriched user experience.
These stories illustrate how Assumira not only meets but exceeds expectations by tailoring digital experiences for diverse industries. Each success reflects its adaptability and effectiveness in creating meaningful change.
The Future of Digital Experiences with Assumira
The future of digital experiences is bright with Assumira leading the charge. This innovative platform is set to redefine how users interact with technology across various sectors.
As businesses embrace change, Assumira’s adaptive solutions will facilitate seamless integration. Companies can expect tailored experiences that resonate deeply with their audiences.
Artificial intelligence and machine learning are at the core of Assumira’s evolution. These technologies will empower organizations to analyze user behavior more effectively, resulting in personalized content delivery.
Collaboration features within Assumira promote teamwork and creativity, driving innovation forward. Remote work has become a norm; this tool ensures teams stay connected and productive regardless of location.
Moreover, as cybersecurity concerns rise, Assumira prioritizes data protection without compromising user experience. The commitment to security builds trust while enhancing engagement opportunities for brands and consumers alike.
Conclusion
Assumira stands at the forefront of digital transformation, reshaping how businesses interact with their customers. Its innovative approach addresses the increasing need for adaptable and efficient solutions in a rapidly evolving digital landscape. By harnessing cutting-edge technology, Assumira empowers organizations to enhance user experiences while driving operational efficiency.
The platform’s key features deliver remarkable benefits that are not just theoretical; they translate into real-world success stories across various industries. Companies leveraging Assumira have reported significant improvements in customer engagement and satisfaction, showcasing its effectiveness.
As we look ahead, it’s clear that Assumira is more than just a tool it’s a vital partner for any business aiming to thrive in the digital age. The future holds even greater potential as Assumira continues to evolve and innovate, ensuring that businesses can adapt seamlessly to new challenges.
With its impressive track record and commitment to excellence, Assumira is set to redefine what’s possible in digital experiences. Embracing this platform means embracing change—a shift toward greater possibilities and improved interactions between brands and their audiences.


 HOME IMPROVEMENT1 year ago
HOME IMPROVEMENT1 year agoThe Do’s and Don’ts of Renting Rubbish Bins for Your Next Renovation
- BUSINESS1 year ago
Exploring the Benefits of Commercial Printing
- HOME IMPROVEMENT10 months ago
Get Your Grout to Gleam With These Easy-To-Follow Tips

 HEALTH10 months ago
HEALTH10 months agoThe Surprising Benefits of Weight Loss Peptides You Need to Know
- TECHNOLOGY1 year ago
Dizipal 608: The Tech Revolution Redefined
- HEALTH10 months ago
Your Guide to Shedding Pounds in the Digital Age
- BUSINESS1 year ago
Brand Visibility with Imprint Now and Custom Poly Mailers
- LAW1 year ago
7 Key Questions to Ask When Hiring a Criminal Lawyer







