
TECHNOLOGY
Unveiling the Power of /gv8ap9jpnwk in Cybersecurity

Welcome to the world of cybersecurity, where threats lurk in the shadows of cyberspace, waiting to exploit vulnerabilities and wreak havoc. In this digital age, safeguarding sensitive information is paramount, making cutting-edge technologies like /gv8ap9jpnwk indispensable. Join us as we unveil the power of /gv8ap9jpnwk in fortifying defenses against cyber threats and securing data with unmatched precision and efficiency.
History and Evolution of /gv8ap9jpnwk
In delving into the history and evolution of /gv8ap9jpnwk, we uncover a fascinating journey through the ever-changing landscape of cybersecurity. Originally conceived as a way to enhance data protection, /gv8ap9jpnwk has evolved into a critical tool in safeguarding digital assets against evolving threats.
The roots of /gv8ap9jpnwk can be traced back to early encryption methods used to secure sensitive information. As technology advanced, so too did the capabilities of /gv8ap9jpnwk, adapting to meet the growing complexity of cyber threats.
Over time, /gv8ap9jpnwk has become an indispensable component of cybersecurity strategies across industries worldwide. Its ability to detect anomalies, identify patterns, and mitigate risks makes it a cornerstone in defending against malicious activities in the digital realm.
As cyber threats continue to evolve, so too will the role of /gv8ap9jpnwk in fortifying our defenses against these ever-present dangers.
Why is /gv8ap9jpnwk important in Cybersecurity?
In the ever-evolving landscape of cybersecurity, the importance of /gv8ap9jpnwk cannot be overstated. This powerful tool plays a crucial role in safeguarding sensitive data and systems from malicious threats. By utilizing advanced algorithms and analytics, /gv8ap9jpnwk helps detect anomalies and potential security breaches in real-time.
With cyber attacks becoming more sophisticated each day, organizations need robust solutions like /gv8ap9jpnwk to stay ahead of cybercriminals. Its ability to analyze vast amounts of data quickly and accurately makes it an indispensable asset for any cybersecurity strategy.
Moreover, /gv8ap9jpnwk can automate threat detection and response processes, saving valuable time and resources for cybersecurity teams. By continuously monitoring network activity and identifying patterns indicative of suspicious behavior, this technology enhances overall security posture.
Integrating /gv8ap9jpnwk into cybersecurity protocols is vital in fortifying defenses against evolving threats in today’s digital age.
Real-life Examples of /gv8ap9jpnwk in Action
In the realm of cybersecurity, /gv8ap9jpnwk plays a crucial role in safeguarding sensitive data and thwarting malicious cyber threats.
One real-life example of /gv8ap9jpnwk in action is its utilization by financial institutions to detect fraudulent activities and protect customer accounts from unauthorized access. By analyzing patterns and anomalies in user behavior, organizations can proactively identify potential security breaches before they escalate.
Moreover, healthcare providers leverage /gv8ap9jpnwk to secure patient information and comply with strict privacy regulations. Through advanced encryption techniques and threat intelligence integration, hospitals can ensure the confidentiality of medical records and maintain trust with their patients.
Additionally, e-commerce platforms rely on /gv8ap9jpnwk to prevent credit card fraud and enhance transaction security for online shoppers. This technology enables businesses to authenticate users, detect suspicious transactions, and mitigate risks associated with online payments.
These real-life examples highlight the diverse applications of /gv8ap9jpnwk across various industries in strengthening cybersecurity defenses against evolving cyber threats.
The Role of Artificial Intelligence in Enhancing /gv8ap9jpnwk
Artificial Intelligence (AI) plays a crucial role in enhancing /gv8ap9jpnwk within cybersecurity. By leveraging AI algorithms, organizations can analyze vast amounts of data in real-time to detect and respond to potential threats proactively.
One significant advantage of AI in cybersecurity is its ability to identify patterns and anomalies that may go unnoticed by traditional security measures. This proactive approach helps prevent cyber attacks before they can cause damage.
Moreover, AI-powered systems can continuously learn and adapt to new threats, making them highly effective in combating evolving cyber threats. These intelligent systems can also automate routine tasks, freeing up human resources to focus on more complex security challenges.
The integration of Artificial Intelligence into cybersecurity strategies has proven to be a game-changer in strengthening defense mechanisms against malicious actors in today’s increasingly digital landscape.
Implementing /gv8ap9jpnwk in Your Cybersecurity Strategy
When it comes to bolstering your cybersecurity defenses, implementing /gv8ap9jpnwk in your strategy is crucial. This powerful tool helps identify and mitigate potential threats before they can cause harm to your systems. By incorporating /gv8ap9jpnwk into your cybersecurity plan, you can stay one step ahead of cyber attackers.
One way to implement /gv8ap9jpnwk is by utilizing advanced algorithms that analyze data patterns and anomalies in real-time. This proactive approach allows you to detect suspicious activities promptly and respond effectively.
Furthermore, integrating /gv8ap9jpnwk with other security measures like firewalls and encryption enhances the overall protection of your network. This multi-layered defense system makes it harder for malicious actors to breach your digital infrastructure.
Incorporating regular updates and patches to your /gv8ap9jpnwk solution is also essential in maintaining its effectiveness against evolving threats. Continuous monitoring and adjustment are key components of a robust cybersecurity strategy that includes this cutting-edge technology.
Challenges
Challenges in implementing /gv8ap9jpnwk’s in cybersecurity can arise from various factors. One of the main challenges is the constantly evolving nature of cyber threats, requiring organizations to stay updated with the latest trends and technologies. This means that cybersecurity professionals need to continuously adapt and enhance their strategies to effectively combat new forms of attacks.
Another challenge is the lack of skilled cybersecurity personnel available in the industry. As cyber threats become more sophisticated, there is a growing demand for professionals who are well-versed in implementing advanced security measures like /gv8ap9jpnwk’s.
Furthermore, integrating /gv8ap9jpnwk’s into existing systems can be complex and time-consuming. Organizations may face compatibility issues or resistance from employees who are not familiar with these technologies. Overcoming these technical hurdles requires careful planning and expertise.
Moreover, ensuring regulatory compliance while using /gv8ap9jpnwk’s adds another layer of complexity. Organizations must navigate through a maze of legal requirements and standards to protect sensitive data effectively.
In conclusion…
Conclusion
Unveiling the Power of /gv8ap9jpnwk in Cybersecurity has provided a comprehensive overview of the importance and impact of this technology in safeguarding digital assets. With its evolution, real-life examples, integration with artificial intelligence, and implementation strategies discussed, it is clear that /gv8ap9jpnwk plays a crucial role in fortifying cybersecurity defenses against evolving threats.
As cyber attacks continue to rise in complexity and frequency, organizations must harness the power of /gv8ap9jpnwk to proactively protect their sensitive information and systems. By understanding the challenges associated with implementing this technology and staying informed about emerging trends, businesses can stay ahead of cyber adversaries and ensure a secure digital environment for their operations.
Incorporating /gv8ap9jpnwk into cybersecurity strategies is not just an option but a necessity in today’s interconnected world. Embracing this innovative approach will empower organizations to defend against sophisticated cyber threats effectively while fostering trust among stakeholders. As we navigate the ever-changing landscape of cybersecurity risks, leveraging the power of /gv8ap9jpnwk will be key to ensuring resilience and continuity in the face of adversarial forces.
FAQs
Q: What is the role of /gv8ap9jpnwk in cybersecurity?
Ans: /gv8ap9jpnwk plays a vital role in cybersecurity by detecting anomalies and mitigating risks in real-time, ensuring the protection of sensitive data against evolving threats.
Q: How has /gv8ap9jpnwk’s evolved over time?
Ans: Originally rooted in encryption for data protection, /gv8ap9jpnwk’s has evolved into a sophisticated tool for identifying and responding to complex cyber threats across diverse industries.
Q: What are the practical applications of /gv8ap9jpnwk’s in cybersecurity?
Ans: /gv8ap9jpnwk’s is used extensively in sectors like finance to detect fraud, healthcare to secure patient records, and e-commerce to safeguard online transactions, highlighting its versatility in data protection.
Q: How does artificial intelligence enhance /gv8ap9jpnwk’s in cybersecurity?
Ans: Artificial intelligence enhances /gv8ap9jpnwk’s by enabling proactive threat detection through advanced data analysis, adapting defenses to new threats, and automating response mechanisms.
Q: How can organizations implement /gv8ap9jpnwk in their cybersecurity strategy effectively?
Ans: Organizations can implement /gv8ap9jpnwk by integrating it with existing security measures, continuously updating protocols, and addressing challenges like skill shortages and regulatory compliance to strengthen their defenses.


Introduction to XCV PANEL
Are you ready to harness the sun’s power and transform your energy consumption? Let’s dive into the world of solar energy with XCV PANEL as your guide. Solar technology is revolutionizing how we think about electricity, offering a cleaner, more sustainable alternative to traditional sources. Whether you’re curious about reducing your carbon footprint or eager to save on energy bills, understanding solar energy can empower you to make informed decisions for your home and future. Join us as we explore everything from the basics of solar panels to financing options that can lighten your investment load. The sun has never been brighter for renewable energy!
What is Solar Energy?
Solar energy is the power harnessed from the sun’s rays. It’s a renewable resource, meaning it won’t run out as long as we have sunlight.
This form of energy can be converted into electricity or heat. Photovoltaic cells capture sunlight and turn it into electrical energy, while solar thermal systems use heat to warm water or air for residential use.
Using solar energy helps reduce reliance on fossil fuels. As a clean source of power, it contributes to lower greenhouse gas emissions.
Beyond environmental benefits, solar technology has advanced significantly over recent years. Modern panels are more efficient than ever before, making them a practical option for many households and businesses.
With growing awareness about climate change and sustainability, interest in solar solutions continues to rise globally. Adopting this natural resource presents an exciting opportunity for innovation and self-sufficiency in energy consumption.
The Benefits of Going Solar XCV PANEL
Transitioning to solar energy with XCV PANEL offers several compelling benefits. First, it significantly reduces electricity bills. As sunlight is free, your reliance on the grid decreases, leading to substantial savings over time.
Another key advantage is environmental impact. Utilizing solar power means decreasing carbon footprints and contributing to a cleaner planet. This shift promotes sustainable living for future generations.
Moreover, many regions provide incentives for adopting solar technology. Tax credits and rebates can make installation more affordable, enhancing return on investment.
Homeowners also enjoy increased property value when installing XCV PANEL systems. Solar installations are often viewed as upgrades that appeal to potential buyers down the line.
Going solar provides energy independence. With your own system generating power, you’re less vulnerable to fluctuating utility rates or outages caused by extreme weather events.
Types of Solar Panels and How They Work
When considering solar energy, understanding the types of solar panels is crucial. The three primary categories consist of monocrystalline, polycrystalline, and thin-film technologies.
Monocrystalline panels are known for their high efficiency. Made from a single crystal structure, they convert sunlight into electricity more effectively than other options. Consequently, they are a perfect fit for rooftops with restricted surface area.
Polycrystalline panels consist of multiple crystals melted together. While slightly less efficient than monocrystalline models, they are often more affordable. They perform well in various weather conditions too.
Thin-film solar panels offer flexibility and lightweight design. They’re made by layering photovoltaic material on different substrates like plastic or metal. Though generally less efficient per square foot, they can be useful in unique applications where traditional panels might not fit.
Each type has its advantages depending on your specific needs and space requirements. Understanding these differences helps you make an informed decision about which panel suits your energy goals best.
Factors to Consider Before Installing Solar XCV PANEL
Before installing the XCV PANEL, it’s essential to evaluate your energy needs. Analyze your past utility bills to understand your consumption patterns. This will help you determine the system size that suits you best.
Next, consider the roof condition and orientation. A south-facing roof with minimal shading is ideal for solar panel efficiency. If repairs are needed, it’s wise to address them before installation.
Check local regulations and incentives as well. Some areas offer tax credits or rebates for solar installations that can significantly reduce costs.
Think about long-term goals. Are you planning any home renovations? Future expansions could impact how much power you’ll need from your XCV PANEL setup down the line.
Financing Options for Solar Energy Systems
Financing solar energy systems can seem daunting, but there are multiple options available to make the transition easier. Many homeowners opt for solar loans, which allow you to pay for your system over time while still benefiting from energy savings.
Leasing is another option worth considering. With a lease, you pay a fixed monthly amount without having to bear the upfront costs. This arrangement often includes maintenance and monitoring services too.
Power Purchase Agreements (PPAs) provide an alternative where you agree to buy electricity produced by the solar panels at a set rate. This allows access to clean energy without any initial investment.
Government incentives can also play a major role in financing decisions. Tax credits and rebates may significantly reduce overall expenses, making solar more affordable than ever before.
Explore these choices carefully; each has unique advantages that could align with your financial situation or goals.
Maintenance and Care for Solar XCV PANEL
Maintaining your XCV PANEL is essential for optimal performance. Regular cleaning is key to removing dirt, dust, and debris that can block sunlight. A simple rinse with water usually does the trick.
Inspecting connections and wiring should be part of your routine check-up. Look for any signs of wear or damage. If something seems off, consulting a professional is wise.
Monitor your energy output periodically. By doing so, you can identify and address prospective problems before they escalate. An unexpected drop in production could indicate a problem with the panels themselves or other components.
Don’t forget about shade management. Trim any trees or plants that may obstruct sunlight from reaching your XCV PANELs during peak hours.
Keeping these tips in mind will help ensure that your solar system runs efficiently for years to come.
Conclusion: Why You Should Make the Switch to Solar Energy?
The shift to solar energy represents a significant opportunity for homeowners and businesses alike. XCV PANEL stands out as an innovative solution that makes harnessing the sun’s power more accessible than ever.
Making the switch to solar not only reduces your carbon footprint but also offers incredible savings on utility bills over time. With various financing options, going solar can be feasible for many budgets. The maintenance requirements are minimal, allowing you to enjoy the benefits without a hefty commitment of time or money.
Investing in XCV PANEL means investing in a sustainable future. As technology advances, solar energy systems become increasingly efficient and cost-effective. Embracing this clean energy source enhances property value while contributing positively to the environment.
Whether you’re motivated by financial incentives or environmental responsibility, adopting solar energy with XCV PANEL is a smart choice that aligns with modern living’s demands and values. It’s about securing both your wallet and our planet’s health for generations to come.

BFG098, often referred to as the Big Friendly Giant in the digital landscape, represents a significant advancement in technology, particularly in the realm of algorithms and computing. It stands as a testament to the continuous evolution of artificial intelligence and its applications across various domains. In this article, we delve into the depths of BFG098, uncovering its origins, functionalities, implications, and much more.
Origins and Development
BFG098 emerged from a collaboration of top-tier researchers and engineers striving to push the boundaries of computational capabilities. The development journey of BFG098 traces back to several years of meticulous research, experimentation, and refinement. Its inception can be attributed to the need for more sophisticated algorithms capable of handling vast datasets and complex tasks with precision and efficiency.
Key Features and Components
BFG098 Algorithm
At the heart of BFG098 lies its groundbreaking algorithm, designed to optimize various processes and tasks in diverse fields. This algorithm incorporates advanced machine learning techniques, including neural networks and deep learning, to analyze data patterns, make predictions, and generate insights.
Applications
The versatility of BFG098 extends across multiple domains, encompassing fields such as finance, healthcare, e-commerce, and more. Its applications range from predictive analytics and recommendation systems to natural language processing and image recognition, catering to a wide spectrum of needs and requirements.
How BFG098 Works
Algorithm Mechanisms
BFG098 operates on the principles of pattern recognition, data analysis, and iterative learning. It leverages vast datasets to train its models, continually refining its algorithms to adapt to evolving scenarios and challenges. Through iterative processes, BFG098 fine-tunes its parameters and adjusts its predictions, ensuring accuracy and reliability.
Implementation
The implementation of BFG098 varies depending on the specific use case and requirements. It can be deployed as a standalone system or integrated into existing platforms and applications seamlessly. The modular architecture of BFG,098 facilitates easy customization and scalability, enabling organizations to leverage its capabilities effectively.
Advantages of BFG098
Improved Performance
One of the primary benefits of BFG098 is its ability to enhance performance across various tasks and operations. By leveraging advanced algorithms and computational techniques, it streamlines processes, reduces latency, and enhances overall efficiency, thereby driving productivity and innovation.
Enhanced User Experience
BFG098 plays a crucial role in enhancing user experiences by delivering personalized recommendations, insights, and services tailored to individual preferences and behaviors. Its ability to analyze vast amounts of data in real-time enables organizations to offer seamless and intuitive experiences to their users, fostering engagement and loyalty.
ALSO READ: EXPLORING THE PHENOMENON OF JOYCIANO
BFG098: Challenges and Limitations
Despite its numerous advantages, BFG098 is not without its challenges and limitations. One of the primary concerns revolves around data privacy and security, as the use of sensitive information for training purposes raises ethical and regulatory questions. Additionally, ensuring the robustness and reliability of BFG,098 algorithms in dynamic and unpredictable environments poses significant challenges.
Use Cases of BFG098
Industry Examples
Several industries have embraced BFG098 to drive innovation and gain a competitive edge. In the finance sector, it facilitates risk assessment, fraud detection, and algorithmic trading, enabling organizations to make informed decisions and mitigate risks effectively. Similarly, in healthcare, BFG,098 powers diagnostic tools, treatment recommendations, and drug discovery efforts, revolutionizing patient care and outcomes.
Future Trends and Potential
The future outlook for BFG098 is promising, with continued advancements expected in algorithms, technologies, and applications. As organizations increasingly rely on data-driven insights to inform their strategies and operations, the demand for sophisticated AI solutions like BFG,098 is poised to grow significantly.
Comparison with Other Technologies
In comparison to traditional algorithms and computing techniques, BFG098 offers unparalleled capabilities in terms of scalability, efficiency, and accuracy. Its adaptive nature and deep learning capabilities set it apart from conventional approaches, making it a preferred choice for organizations seeking to harness the power of AI.
ALSO READ: WHAT IS AMAZONS GPT55X?
Security and Privacy Concerns
Addressing security and privacy concerns is paramount in the adoption and deployment of BFG,098. Organizations must implement robust security measures and adhere to regulatory frameworks to safeguard sensitive data and ensure compliance with privacy regulations.
Ethical Considerations
Ethical considerations surrounding the use of BFG,098 encompass issues such as bias, transparency, and accountability. As AI algorithms influence critical decisions and outcomes, it is essential to mitigate biases and ensure fairness in algorithmic processes. Transparency and accountability are also vital to fostering trust and confidence in AI systems among users and stakeholders.
Conclusion
In conclusion, BFG098 represents a transformative force in the realm of artificial intelligence and computing. Its advanced algorithms, coupled with its wide-ranging applications, hold immense potential to drive innovation, enhance productivity, and improve the quality of life. However, addressing challenges related to security, privacy, and ethics is essential to realizing the full benefits of BFG,098 responsibly.
ALSO READ: HD D FDSJ: EXPLORING HIGH-DEFINITION DISPLAYS
FAQs
What sets BFG098 apart from other algorithms?
BFG098 distinguishes itself through its advanced machine learning techniques and deep learning capabilities, enabling it to handle complex tasks and vast datasets with precision and efficiency.
How can organizations leverage BFG098 effectively?
Organizations can leverage BFG,098 to enhance performance, drive innovation, and gain actionable insights from their data. By integrating BFG,098 into their workflows and systems, they can unlock new opportunities and stay ahead of the competition.
What are some potential challenges associated with implementing BFG098?
Challenges associated with implementing BFG,098 include data privacy and security concerns, algorithm robustness, and ethical considerations. Addressing these challenges requires careful planning, collaboration, and adherence to best practices.
Is BFG098 suitable for small businesses and startups?
While BFG098 offers significant benefits in terms of performance and efficiency, its implementation may require substantial resources and expertise. Small businesses and startups should carefully evaluate their needs and capabilities before integrating BFG,098 into their operations.
What does the future hold for BFG098?
The future of BFG,098 looks promising, with ongoing advancements in AI technologies and applications. As organizations continue to embrace AI-driven solutions, BFG,098 is poised to play a pivotal role in shaping the future of computing and innovation.
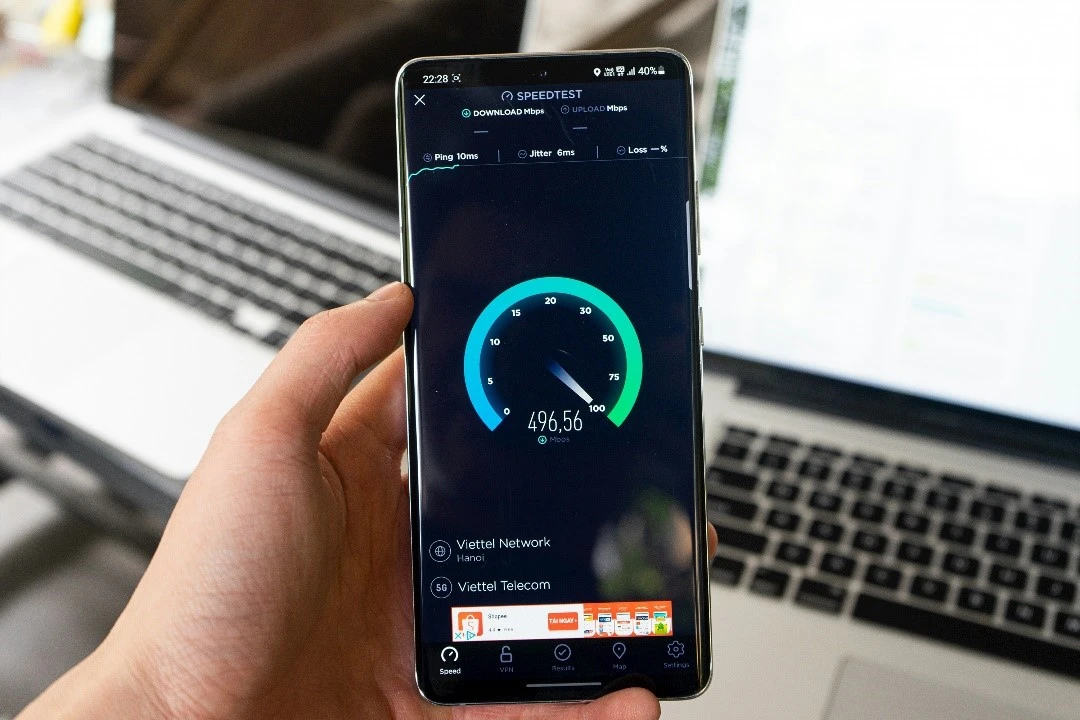
In the past few years, we saw 5G completely engulf the world of smartphone and internet technology. Not many of us knew the full scale of 5G, like the fact that 5G has the potential to replace your conventional internet connection. Well, the idea of getting rid of messy wires sure is tempting but there are several factors to consider before making that call.
In this blog, we will discuss the advantages and disadvantages of 5G and how it measures up against other wired and wireless connections.
In This Blog
Advantages of 5G.. 1
1. Lower Latency Than Satellite Internet 1
2. No Need for Clear Line of Sight Like WISPs. 1
3. Cost 2
4. Better Coverage and Accessibility. 2
5. Convenience. 2
Disadvantages of 5G.. 2
1. Performance. 2
2. Speed Tiers. 3
3. Upload Speeds. 3
Summing Up. 3
Advantages of 5G
Let’s discuss some advantages and other implications of getting 5G for your home.
1. Lower Latency Than Satellite Internet
Wireless internet technology for homes is not an entirely new concept. Satellite internet provides online connection; however, 5G is an improved wireless technology. With all its virtues, satellite internet still bogs you down with limited speeds, range, and latency.
It suffices for activities that are not data-intensive, like browsing, but for real-time applications, you need a stronger connection.
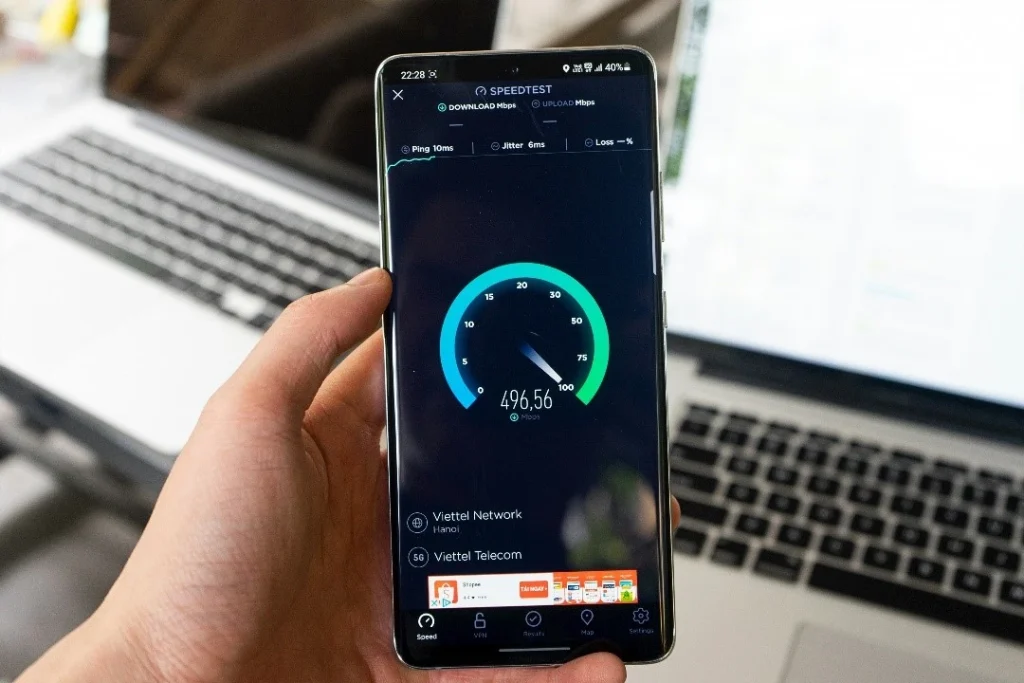
2. No Need for Clear Line of Sight Like WISPs
There are also Wireless Internet Service Providers(WISPs) that commonly use frequencies other than 5G to beam internet signals from access points on towers or buildings to home modems. They do this with the help of attached antennas.
Even though WISPs minimize latency issues, there is still a requirement for a clear line of sight between the access point and the home antenna to ensure a unidirectional beam of signals. 5G provides high speed and low latency without needing a clear line of sight.
3. Cost
This advantage is subject to the kind of providers available in your area and the packages they offer. Typically, a 5G connection costs an economical amount for an adequate signal compared to wired connections.
The cherry on top would be if you can find a 5G connection from your existing provider, you may be able to find a nice bundle package with both connections.
4. Better Coverage and Accessibility
Satellite internet Providers and WISPs usually target folks in underserved rural areas who might not have adequate options for a wired internet service. 5G is making inroads even in areas where consumers could easily get cable or fiber. This fulfills a need for an accessible and improved wireless internet connection.
5. Convenience
Convenience is a big draw that 5G offers. If you don’t already have cable or fiber lines running to your house, you don’t have to wait around for a technician to come and do an installation between specified hours. Not to mention, you can finally get rid of that horrid bunch of wires.
Even if you have a cable or fiber connection, 5G eliminates the complications of ethernet jacks and modem placements. All you have to do is plug in a 5G receiver wherever you can find a power socket.
Disadvantages of 5G
Despite the aforementioned advantages, 5G also has some potential pitfalls. Let’s expand on them.
1. Performance
How well your 5G connection performs is completely dependent on the quality of the 5G signals you get in your house. 5G speeds simply aren’t high enough everywhere to compete with cable or fiber. One strategy is to run a speed test to get a rough idea of the performance you’ll get with home 5G.
As for performance, you can expect speed and latency to fluctuate more, compared to a wired connection which can be much more stable. This is because the network tends to have variable loads and wireless signals are dominantly inconsistent. If you’re looking for an internet for things that need a stable connection, its better to go for internet, like the one offered by Spectrum, rather than a 5G provider.
2. Speed Tiers
How well your 5G connection works is also subjective to various speed tiers. The ultra-fast one has a very short-range, millimeter wave. The low band 5G does not differ much from 4G LTE in terms of performance. Here’s the snag, some of the faster versions of 5G don’t penetrate through walls as well as 4G.
If you’re in doubt about exactly what kind of 5G technology and ISP you’re considering, make sure you do your research. This is because some providers that advertise 5G will often fall back to a 4G LTE connection if the actual 5G connection reaching your home is not strong enough.
A lower band connection can give you better signal strength, which comes at the cost of slower speeds. Low band 5G, around 700 megahertz, is often marketed as rural broadband with reliability as a big selling point.
3. Upload Speeds
Considering you have an ISP in your area offering fiber, they’ll usually offer upload speeds that are just as fast as download speeds. This is the case with most home cable connections. However, when it comes to 5G, you might you may experience some choppy upload speeds with 5G home internet.
Summing Up
Latency is not a big factor if you’re just trying to download large files or watch YouTube. If you’re in an area with good 5G coverage, and aren’t super worried about online gaming performance or video conferencing, 5G home internet might just be worth looking into. But, for someone who wants a reliable, stable connection, fiber internet is still something you should get.


 HOME IMPROVEMENT1 year ago
HOME IMPROVEMENT1 year agoThe Do’s and Don’ts of Renting Rubbish Bins for Your Next Renovation
- BUSINESS1 year ago
Exploring the Benefits of Commercial Printing
- HOME IMPROVEMENT10 months ago
Get Your Grout to Gleam With These Easy-To-Follow Tips

 HEALTH10 months ago
HEALTH10 months agoThe Surprising Benefits of Weight Loss Peptides You Need to Know
- TECHNOLOGY1 year ago
Dizipal 608: The Tech Revolution Redefined
- HEALTH10 months ago
Your Guide to Shedding Pounds in the Digital Age
- BUSINESS1 year ago
Brand Visibility with Imprint Now and Custom Poly Mailers
- LAW1 year ago
7 Key Questions to Ask When Hiring a Criminal Lawyer







